|
I am second-year data science graduate student in the School of Informatics, Computing, and Engineering at the Indiana University, Bloomington. I have keen interest in machine learning and its application in computer vision, natural language processing, and data science. My graduate course curriculum includes Elements of Artificial Intelligence, Applied Algorithms, Statistical Inference, Data Mining, Exploratory Data Analysis, Machine Learning in Computational Linguistics, Machine Learning in Signal Processing, Advance Database Concepts. Prior to my graduate studies, I was working as a Senior Project Associate at the Indian Institute of Technology (IIT) - Kanpur where I developed a Data Visualization Web Application under the advice of Prof. Arnab Bhattacharya and a Vehicle Recognition System under the supervision of Prof. Gaurav Pandey. I have previously worked with Ipsos Research, a leading global market research firm at Bangalore office and two technology startups: Tinyowl (now, merged with Runnr) with the business intelligence team and at Embibe with the data team. I have completed my undergraduate studies from the Indian Institute of Technology (IIT) - Kharagpur in 2013. Email | CV | LinkedIn | Github | Random clicks |

|
|
|
|
|
|
During the my internship at Altair, I worked on multiple projects. In my first project, I developed a 3D shape recognition system using voxelization and 3D Convolutional Neural Nets (CNN) resulting in 87% accuracy on the Princeton ModelNet10 (CAD models) dataset. In the second project, I built a multi-layered neural network to predict the failure of an Air Pressure System (APS) for Scania Trucks in order to minimize the maintenance cost (Industrial Challenge 2016 at The 15th International Symposium on Intelligent Data Analysis (IDA)). The resulting models's performance was better than the results of teams that stood second and third in the competition. In another project, I built a system using deep neural nets to predict reduction in mass for a given geometry and load condition in order to achieve an optimized structure which could potentially reduce human efforts needed to run multiple simulation runs. |
|
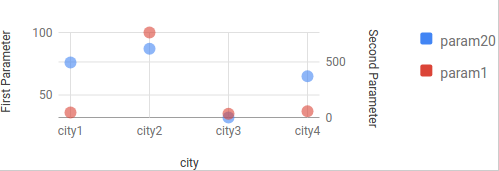
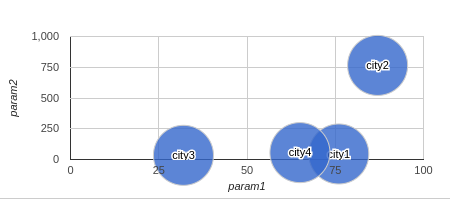
Developed a web-based user interactive application in PHP for real-time management and visualization of data stored in MySQL database. Defined the complete database schema, configured, and deployed the same using phpMyAdmin. Implemented device responsiveness and interoperability using the Bootstrap framework. Integrated the Google chart API to visualize the variability of data parameters in terms of distribution, trend, correlation, deviation, ratio, and frequency |
 
|
Built a Python based OCR system to identify characters of number plates employing template matching framework. Performed various image processing activities, such as Morphological transformations, Adaptive histogram equalization, contour formation etc. using OpenCV library. The algorithm iterates over different pixel values as a threshold for binarization of gray-scaled images. The segmented binarized characters are then compared with existing templates for identification. It produced an accuracy of 83% in comparison to 76% with the existing one when tested over 1000 images. |
|
|
I led several high-impact projects aimed towards growth. I collaborated with the marketing team to develop systems that drove the marketing efforts. In the process, I built a Logistic Regression Model to predict the propensity of user retention and developed a system employing k-means clustering for consumer segmentation to mimic consumption patterns in order to optimize marketing ROI. During my tenure, I also devised an algorithm aimed to rank restaurants based on their performance where I implemented scoring algorithm using Gini coefficients and centroid method to allocate weights to different contributing factors. In one of my project, I built an internal dashboard to visualize and track multiple business metrices using shiny package in R. |
|
|
I worked as a Market Research Analyst for IPSOS. As part of my job profile, I conducted brand tracking and Return-on-Investment evaluation per marketing tactic by creating and assessing Market Mix Models of various market scenarios. I also developed optimization strategies for effective marketing expenditure and developed predictive models to forecast accrued profits. I worked in a global team and collaborate on a day-to-day basis with my offshore colleagues based in New York and Connecticut. I have also acted on numerous occasions as key accounts manager for my firm serving numerous global clients in a variety of domains covering retail, CPG, pharmaceuticals, restaurant chains. For my outstanding perfomance, I was also awarded with Spot Performer of Q3'2014 in the analytics domain. |
|
|
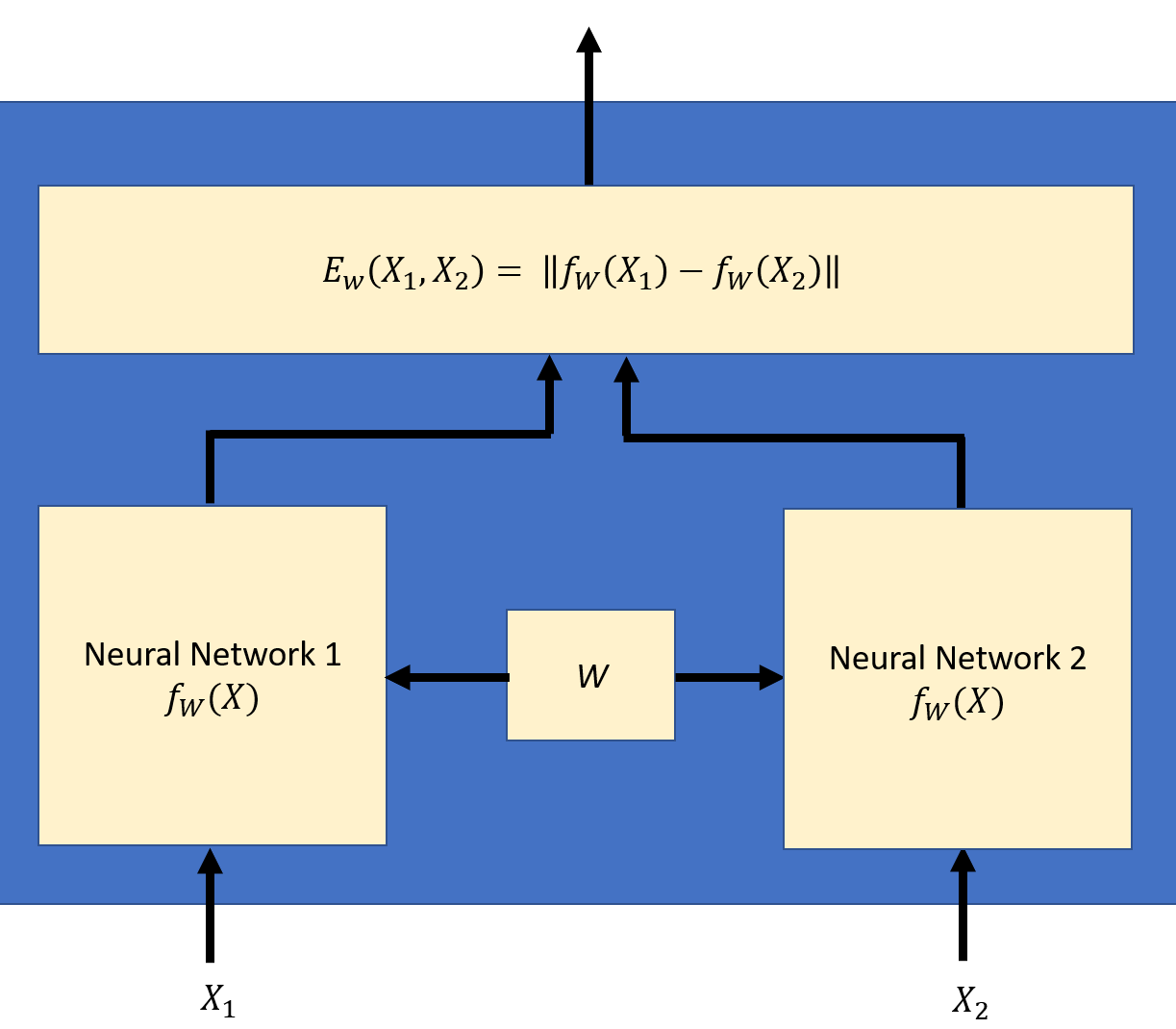 |
Designed a Siamese network based on VGGVox model as sister networks sharing common set of weights. Trained the model on VoxCeleb dataset on AWS. Performed transfer learning and used pretrained weights of the VGGVox model. The VoxCeleb dataset contains speech from speakers spanning a wide range of different ethnicities, accents, professions and ages. It consists of 100K utterances for 1,251 celebrities. Transformed recordings to a magnitude spectogram using STFT, with a frame size of 15 milliseconds and an overlap of 15 milliseconds. Achieved 0.78 precision & 0.84 recall. Developed a terminal application for identification and verification in real time. |
 |
Working towards deep learning specialization course provided by deeplearning.ai and Coursera. Worked on projects involving the implementation of deep neural networks from scratch, exploring and tuning multiple hyperparameters of neural networks, different optimization techniques, regularization methods; trained deep neural network on SIGNS dataset to identify hand gesture from a given image. RNN, LSTM architectures using word embeddings (Word2Vec, Glove) for sequence modeling, NLP in particular. |
 |
Explored different deep learning architectures, namely, AlexNet, VGG16, ResNet. Built an image classification model using transfer learning and fine-tuning in Pytorch. AlexNet-78%, VGGNet-85%, ResNet-83% on 10K test images. |
 |
Built an application using Twitter API, Tweepy, and PySpark to connect with Twitter and process live incoming tweets in order to visualize top trending hashtags associated with a given topic |
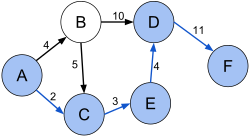 |
Worked on a project aimed at finding the most optimal route between a given pair of cities of the United States. Compared different Graph Search Algorithms, namely, Breadth First Search, Depth First Search, Uniform Cost Search, and A-star on the basis of path cost, time, & space requirements for multiple cost functions |
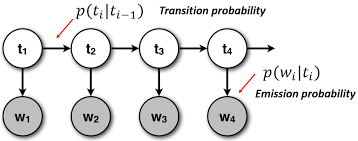 |
Developed a model to perform part-of-speech tagging in English language using Hidden Markov Model, Bayesian inferences, and naive Bayes. Trained the model to calculate initial, transition, emission, and state probabilities on a data consisting of nearly 1 million words and 50,000 sentences. Implemented and compared the performance of Variable Elimination (Forward-Backward Algorithm) and Viterbi Algorithm. Final model resulted in above 50% sentence accuracy and above 90% word accuracy when tested over 2000 sentences. |
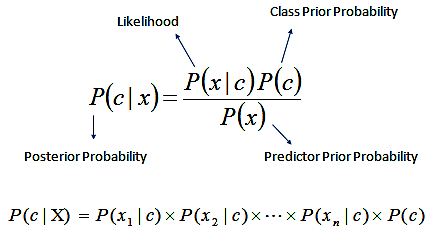 |
Developed a Naive Bayes classifier to identify the location from where the tweet was written by maximizing the likelihood in order to compare posteriors of all cities. Implemented Multinomial Document Model using bag-of-words and Laplace Smoothening for missing tokens |
 |
Developed a N-Queens and N-Rooks solver incorporating Breadth First Search and Depth First Search algorithms |
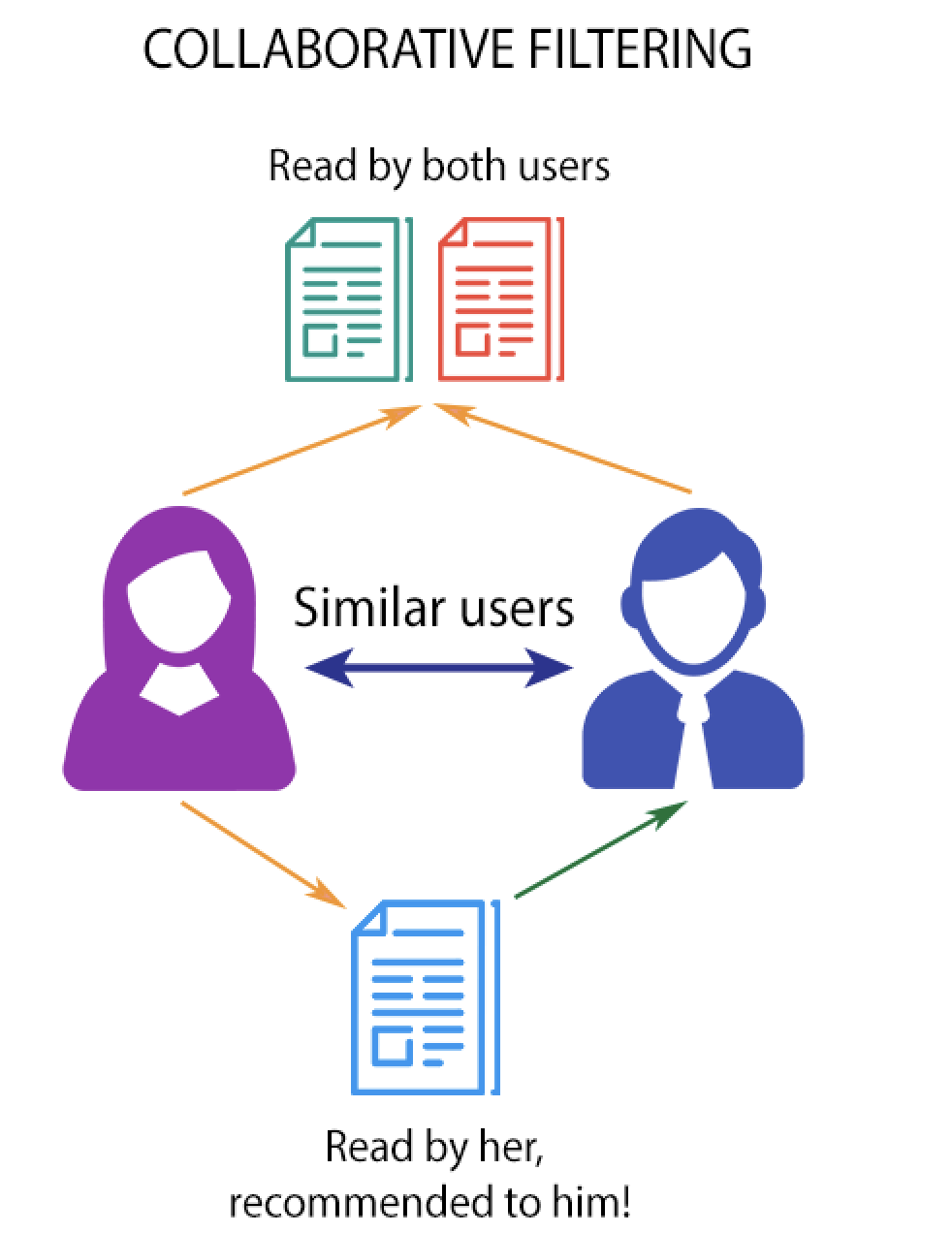 |
Built a Movie Recommendation System in Python based on Collaborative Filtering algorithm that uses Euclidean Distance or Pearson Coefficient to find similar users and returns the list of top recommended movies for a given user. It takes method to be used to find similar users and a number of movies to be recommended as a command line argument. Used MovieLens movies rating dataset from GroupLens. |
|
Credits: Jon Barron |